Given enough eyes, all bugs are shallow
We had a little technical drama at PoliMonitor this morning (we’re not the only ones, as you’ll see).
At some point overnight, Twitter (now X) changed something. From that point on, instead of getting tweets from their servers, we just started getting empty responses. It just stopped returning anything. No error messages, no warnings, no hints, just blank responses. It’s basically the technical equivalent of shrugging your shoulders and smiling.
From a quick look on Twitter/X it seemed that we weren’t the only ones having a problem …

I can empathise with Jay … but it’s even more annoying when you’re paying a lot of money to access the service. But that’s an issue for another day as this morning we need to get the service back up and running again.
We use an open source library to access Twitter’s servers. That’s basically some code that other people have written to make it easier for everyone else. It takes care of things like authentication, networking protocols, data formatting etc. Another user had reported an issue (at the time the ticket was just 13 minutes old), detailing the problem and suggesting a root cause. This was enough for me to crack open the library and replace the faulty component. With the new code pushed to our servers and a quick backfill of the tweets that happened during the outage, we were back up and running before 9am (just 32 minutes after the ticket was first created) … the vast majority of our clients will not have been affected at all.
But the story doesn’t stop there. We’re dealing with an open source project and that comes with responsibilities. I added my fix to the original ticket so that others could benefit from it too.
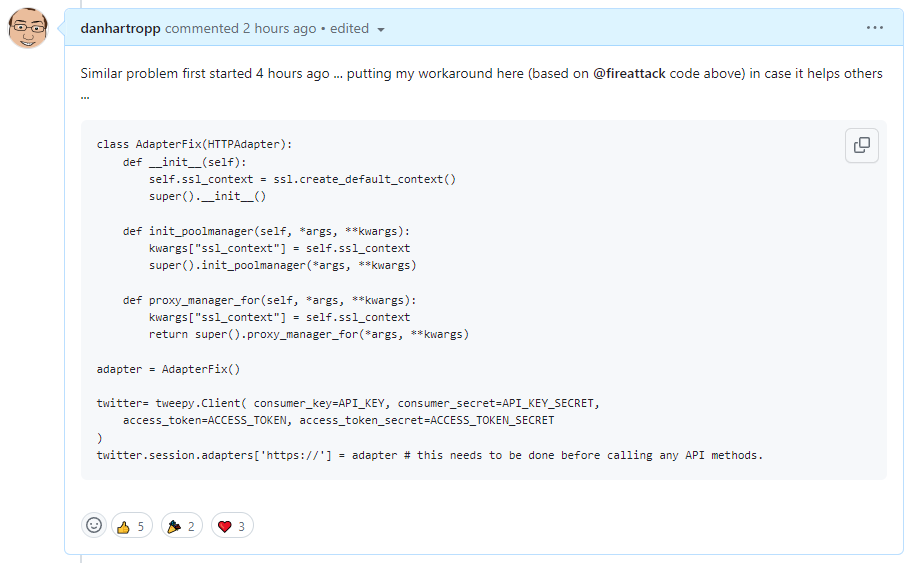
Eventually, this code (or something like it) will be merged into the main code case. In the meantime, a workaround is available.
And that’s the whole point of this blog post. There is no way that I’d have been able to fix this on my own. The underlying problem was caused by a really esoteric network setting that I’d never even heard of before. By providing a place for people to identify problems and help fix them, the maintainers of this software library have enabled a very rapid fix to a problem that they didn’t even cause.
I know there’s a lot of scepticism about open source software and whether it’s sustainable, or even desirable, from a business perspective - but that scepticism largely comes from people who don’t fully understand how complex modern software ecosystems are. There are thousands of moving parts that all have to be kept in sync. It is rare for even large companies to have enough in-house expertise to understand all of the code they use. The tech behemoths (think Google, Facebook etc) that might have this kind of expertise in-house all make source code open to the public, because they know that the benefits of doing so outweigh the commercial costs.
There is, of course, a balance to be struck between opening code that implements business logic and code that enables business processes. Opening the former allows someone to copy your business, but opening the latter allows someone to copy your code - and help improve it.
It slightly scares me that Linus’s Law is nearly 25 years old, but it was definitely still true about two hours ago.
“Given enough eyes, all bugs are shallow.”